Toward Mechanistic Interpretability of LLM Agents: Explaining Trajectories Demands New Methods
Abstract
Mechanistic Interpretability (MI) has made significant progress in explaining the internal computations of Large Language Models (LLMs), yet its application to LLM-based agents remains almost entirely absent from the literature. This position paper argues that MI tools must evolve to target planning and trajectory formation in order to extract actionable insights from LLM agents. We propose a taxonomy distinguishing two levels of agent failure: surface-level failures, that are due to incorrect localized surface generation, and trajectory-level failures, where the failures evolve over trajectories. We argue that current MI tools can be insufficient for explaining trajectory-level failures and may need substantial extensions before they are able to do so. We illustrate this using a case study of web page element hallucination in web agents, and show that standard MI tools capture only part of the problem. We then identify some research directions to make MI practical for LLM-based agents.
Background: LLM Agents and Mechanistic Interpretability
LLM Agents
LLM agents operate over interconnected components across a sequence of timesteps: Perception converts raw observations into token representations; Memory maintains information across timesteps through a history state, taking the form of working memory (the current context window) and long-term memory (parametric knowledge and external retrieval); Reasoning transforms perception and memory into a decision, often through explicit reasoning chains but can also be implicit; Actions are executed by an external environment, yielding a new observation; and Evaluation and Monitoring close the loop by comparing actual and predicted outcomes, and replanning when needed.
Mechanistic Interpretability
MI seeks to explain model behavior by identifying internal mechanisms responsible for it, operating directly on weights, activations, and their causal relationships rather than input-output behavior alone. It is often organized around three key constructs: circuits are computational subgraphs executing identifiable algorithms (e.g., copying, induction) that map information flows and causal responsibility for specific behaviors; features are interpretable directions in activation space representing concepts; and universality denotes the recurrence of features and circuits across architectures.
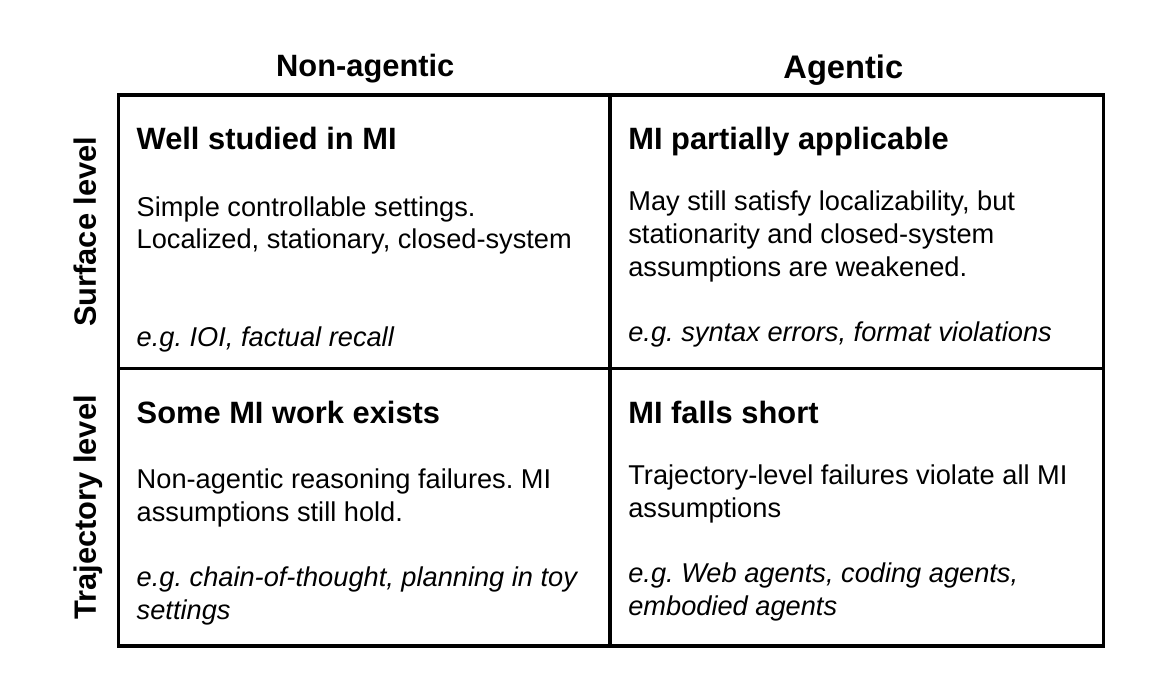
While MI has yielded insightful explanations across a range of tasks, these have largely targeted well-scoped, stationary settings. There is growing consensus that the field must move toward more complex real-world scenarios. The application of MI to agentic settings remains scarce, with existing work confined to sequential decision-making in toy environments or static settings, leaving the mechanistic origins of agent failures in more realistic scenarios poorly understood.
Two Types of Agent Failures
We propose a taxonomy that distinguishes agent failures based on the level at which they originate.
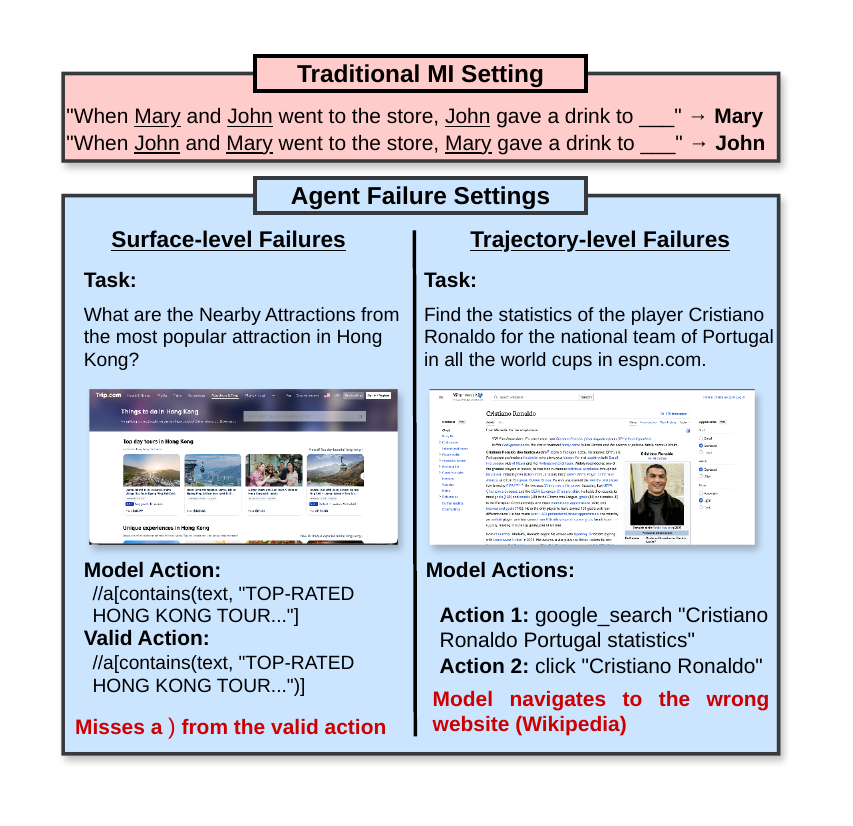
Surface-level failures
These are errors in which the model generates incorrectly at the surface: producing a malformed argument, retrieving an incorrect fact from parametric memory, or generating a syntactically invalid command. These failures share key properties with the settings where MI has succeeded — the error is visible in the output, attributable to a small set of components, and isolable to a single forward pass.
Trajectory-level failures
These are errors that evolve across multiple timesteps and environment interactions. The output may be locally coherent and syntactically correct; the error lies in what the model decided to do. This can emerge from a single wrong decision that propagates into a coherent but invalid action — for instance, an agent misjudging whether an action is feasible given the current environment state — or from a series of beliefs and decisions that accumulate over a trajectory, producing behaviors such as goal drift or over-persistence in the face of contradicting evidence.
Trajectory-level failures are harder to diagnose mechanistically: by the time the wrong token is generated, the model has already committed to the wrong plan. Intervening at the output level cannot address a failure that originated upstream in the model's strategy formation. We argue that MI needs more work to address this kind of failure.
Why Current MI Tools Struggle
The success of MI has been built on three implicit assumptions that hold in static, well-scoped tasks but break down in agentic settings.
Localizability
Standard MI methods assume that failures can be attributed to a small set of positions or components within a single forward pass. In subject-verb agreement, minimal pairs can be constructed by hand, making it straightforward to identify the relevant heads. In factual recall, corrupting a single subject token cleanly shifts the output. In agentic settings, decisions involve complex interactions across many input positions — action histories, environment observations, task descriptions — and there is often no principled basis for hypothesizing which positions or components drive an outcome.
Stationarity
Activation patching and counterfactual methods require a fixed, comparable baseline: a clean run and a corrupted run on near-identical prompts differing in one controlled dimension. In agentic settings, different actions come from entirely different pages, tasks, URLs, and action histories. After each step, the context window grows and the environment state changes. There is no stable baseline, and no guarantee that the timestep where a failure manifests is the same as the one where it originated.
Closed-system assumption
MI methods operate entirely within the model. In static tasks this is sufficient. In agentic settings, the same model computation can lead to different outcomes depending on the environment state at the time of execution. The failure is jointly determined by internal model computation and external environment dynamics — something current MI methods have no framework for reasoning about.
How do these challenges apply to circuit discovery?
The successful applications of circuit discovery methods share implicit assumptions that can fail in agentic settings.
The first assumption, localizability, concerns whether the mechanisms responsible for a model's behavior can be attributed to a small set of positions or components within a single timestep. In subject-verb agreement, minimal pairs can be constructed by hand, making it straightforward to identify the subject token and apply attribution methods that localize the relevant attention heads or FFNs. In agentic settings, this assumption is harder to satisfy: decisions involve complex interactions across many input positions, and there is often no clear basis for hypothesizing which positions or components drive an outcome. Moreover, no single component bears a disproportionate share of the load — many components contribute collectively in ways that single-component attribution methods can struggle to detect.
The second assumption, stationarity, breaks down because the input distribution changes at every timestep. Standard counterfactual methods such as activation patching require a fixed clean baseline; but in an agentic setting, after each action the context window grows and the environment state changes, so no two steps share a comparable baseline. Furthermore, there is no guarantee that the timestep where a failure manifests is the same as the one where it originates: an incorrect decision taken at step t−k produces k steps that execute properly before encountering an undesirable outcome, meaning attribution methods risk analyzing the wrong point in the trajectory.
The third assumption, the closed-system assumption, breaks down because the environment dynamics are external to the model and can vary unpredictably across task instances. The same model computation can lead to different outcomes depending on the environment state at the time of execution. Current MI methods operate entirely within the model and have no framework for reasoning about this kind of cross-boundary causality.
How do these challenges apply to feature identification methods?
Data distribution: SAEs are trained to decompose activations into interpretable features reflecting what is statistically prevalent in their training corpus. Without agent-specific data, they may not capture concepts relevant to agentic behavior — goal tracking, tool selection, multi-step planning — which arise from environment interaction rather than text. Prior work shows that SAE performance degrades under covariate shift, which naturally suggests limited robustness when applying them to agent trajectories.
Probing classifiers face a related issue: the linear structure they rely on can vary over the course of a multi-turn conversation and can be brittle under distribution shifts introduced by changes to the agent's environment or prompt format.
Steering vectors assume the identified direction transfers to the target setting, but distribution shifts can move representations out of the subspace the intervention vector was designed on.
Temporal locality: Agent decisions are not necessarily encoded in a single feature at a single timestep. Commitment to a plan may be distributed across multiple features and emerge gradually over the course of a trajectory, with no single timestep at which the decision is cleanly represented.
Case Study: Why Do Web Agents Hallucinate Website Elements?
To ground our position, we study a concrete failure mode: web page element hallucination. When navigating websites using a minimal action space (CLICK, SCROLL, TYPE, HOVER), LLM agents sometimes generate actions referencing page elements that do not exist — fabricating selectors, buttons, or input fields with no counterpart on the actual page.

We study this using Qwen2.5-7B-Instruct on the Online-Mind2Web dataset (Xue et al., 2025), which collects interaction episodes on live websites. We provide the model with a list of possible actions on each page and define a hallucinated action as one where the agent generates something not in that list. The dataset covers 300 episodes and 2,071 actions, of which 32.6% are hallucinated.
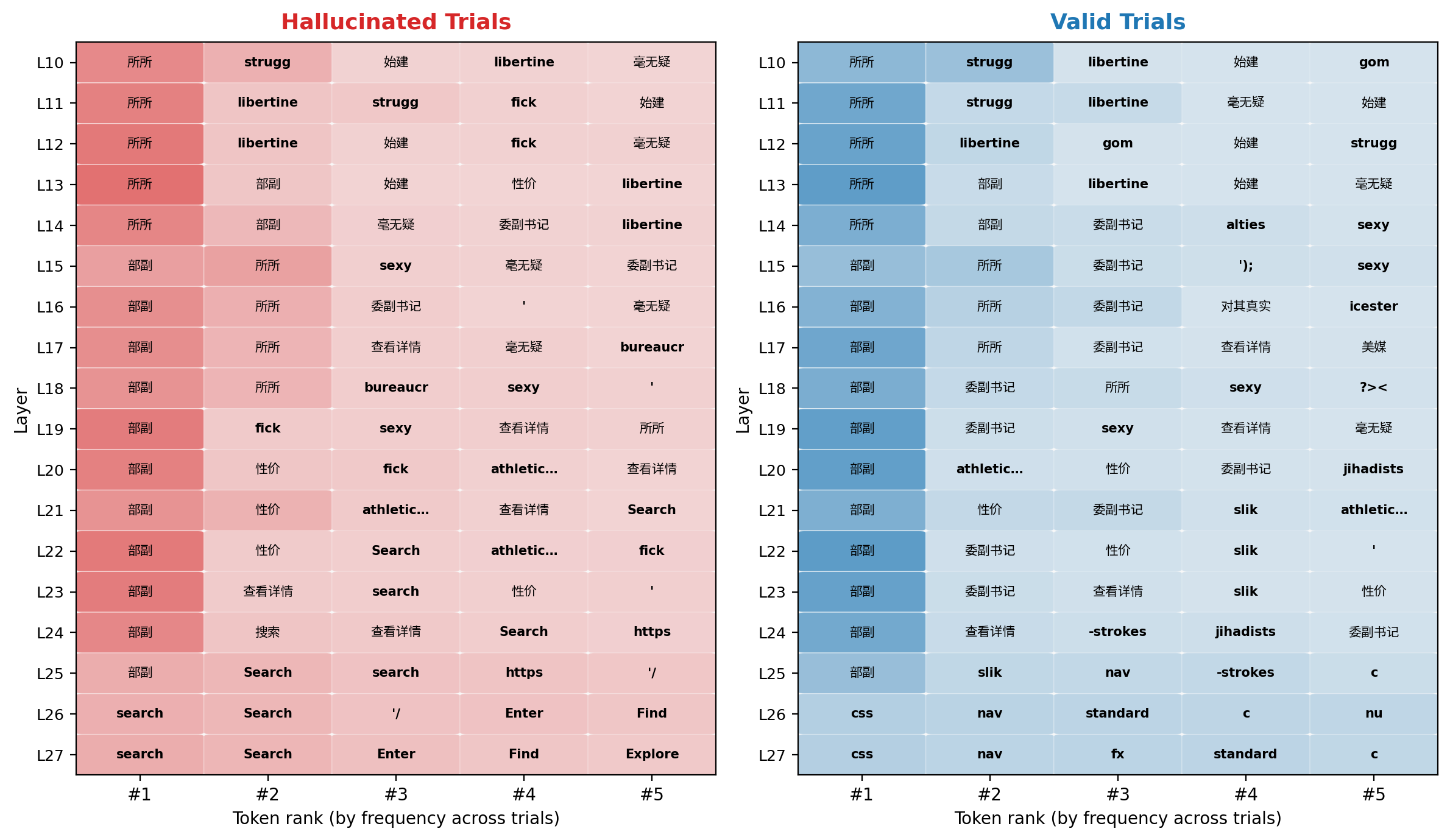
A logit lens analysis reveals that by layers 21–27, hallucinating trials converge on stable, semantically coherent but nonexistent action labels (e.g., "Search", "Explore", "Find"), while valid trials converge on correct page-specific tokens. The model appears to commit to a generic intent before grounding itself in the actual page content — a hallmark of a trajectory-level failure.
Observation 1 Localizability of Responsible LM Components is Violated: Web Element Generation is a Distributed Computation
We test which components are responsible for hallucination by amplifying each FFN layer's output by 10× (one at a time) and by injecting Gaussian noise into each attention head independently, measuring the change in the probability of a valid token at the selector_value_start position.
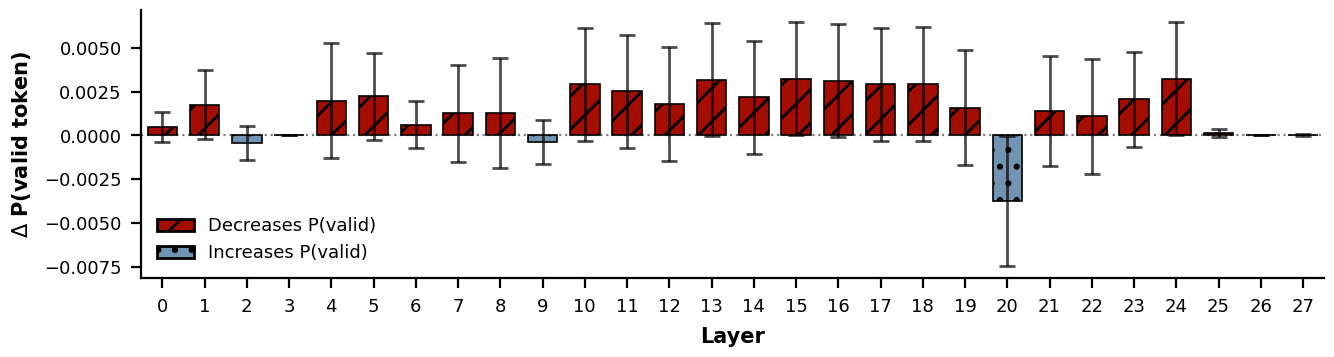
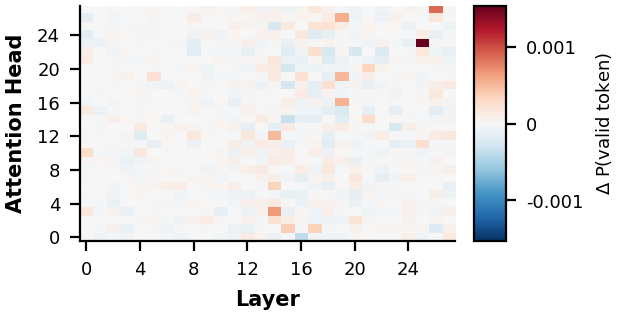
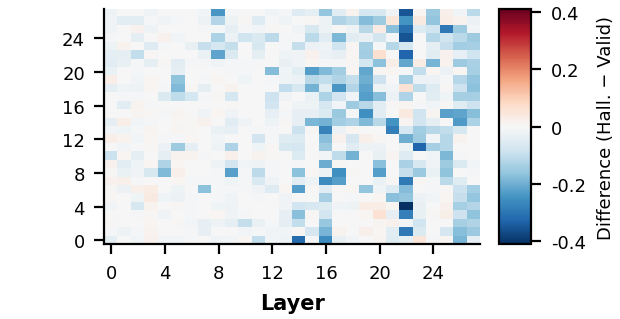
Most FFNs and attention heads individually contribute little to the failure. Critically, when FFN amplification does induce a hallucination, the result is qualitatively different from natural hallucinations. Amplifying layer 15, for example, transforms a valid selector into VAR-1000000000... — syntactically broken — whereas natural hallucinations like Search make, model, or keyword are well-formed and reflect coherent but nonexistent intent. This suggests no individual component bears disproportionate responsibility for the failure.
We further test joint interventions, scaling sets of FFN layers by a coefficient β and attention heads by α:
| Attention Heads | FFN Layers | Fix (↑) | Break (↓) |
|---|---|---|---|
| L22 (all heads) | 22, 23, 24 | 8.9% | 2.4% |
| L22, L27 (all heads) | 22, 23, 24 | 5.9% | 21.7% |
| Top-10 causal (attn noise) | 13, 15, 24 | 4.4% | 3.5% |
| Top-10 causal (attn noise) | 22, 23, 24 | 4.5% | 4.6% |
| Top-10 corr. diff. | 22, 23, 24 | 6.3% | 2.5% |
The best configuration — amplifying all attention heads at layer 22 while halving FFN contributions at layers 22–24 — fixes only 8.9% of hallucinated cases while corrupting 2.4% of valid ones. If the computation were localized, targeted interventions should produce consistent improvements; the fact that they do not suggests the failure is distributed and coupled in a way that single-component attribution cannot fully explain.
Observation 2 Localizability of Responsible Input Positions is Violated: The Action List is a Contributor, but the Specific Positions and Properties Responsible Remain Unidentifiable
Activation patching confirms the action list as a causal contributor: corrupting it produces the largest drop in P("Search"), and restoring clean states at layer 27 recovers up to 0.36 probability mass — far more than corrupting the task description or selector start. However, identifying the action list as a contributor is only a partial result. Unlike factual recall — where knowing that the subject token is causal immediately suggests a targeted intervention (e.g., replacing "Eiffel Tower" with "Colosseum" shifts the output from "Paris" to "Rome") — knowing that the action list matters does not reveal which of its properties drives the commitment, leaving no clear handle for intervention.
Observation 3 Stationarity is Violated: Attempting to Construct Counterfactuals Introduces Cascading Divergence
Activation patching requires pairing a clean trial (valid output) with a counterfactual trial (wrong output) on near-identical prompts that differ in one controlled dimension. In our setting, this is not possible: different actions come from entirely different pages, tasks, URLs, and action histories. Attempting to construct counterfactuals by removing the chosen action from valid trials reveals two issues: first, only 38% of such perturbations actually yield a corresponding hallucinated output — in the other 62% of cases the model simply chooses an alternative valid action. Furthermore, this produces cascading divergence, and the similarity between subsequent pages drops sharply after a single step, rendering the two trajectories incomparable.
Observation 4 Temporal Locality is Violated: The Hallucination Decision is Already Encoded Pre-Generation
We train linear probes on the residual stream at three positions: prompt_end (before any output token is generated), selector_start, and selector_value_start. Probes are trained independently at each of the 28 layers using an episode-level split (300 episodes, 70/15/15 train/dev/test).
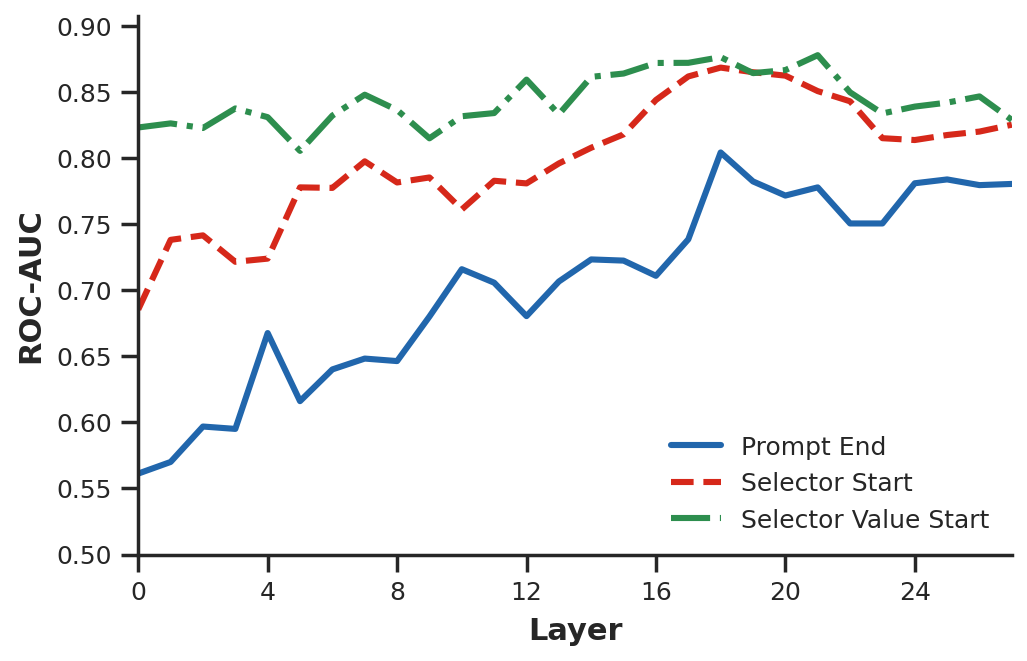
prompt_end reaches AUC 0.80 by layer 18, before the model has produced any output.All three positions yield probes well above chance. A probe trained on pre-generation activations at prompt_end reaches test AUC 0.80 by layer 18 — before the model has produced a single output token. By selector_value_start, the signal is strong from layer 0. This suggests the model's commitment to a hallucinated action is already encoded as a linearly separable direction in the residual stream before generation begins, and may be influenced by context accumulated across previous timesteps. This violates temporal locality: the failure is not encoded at the timestep where it manifests.
Observation 5 Distributional Mismatch of Linear Probing: The Identified Direction is Coupled to the Agentic Design
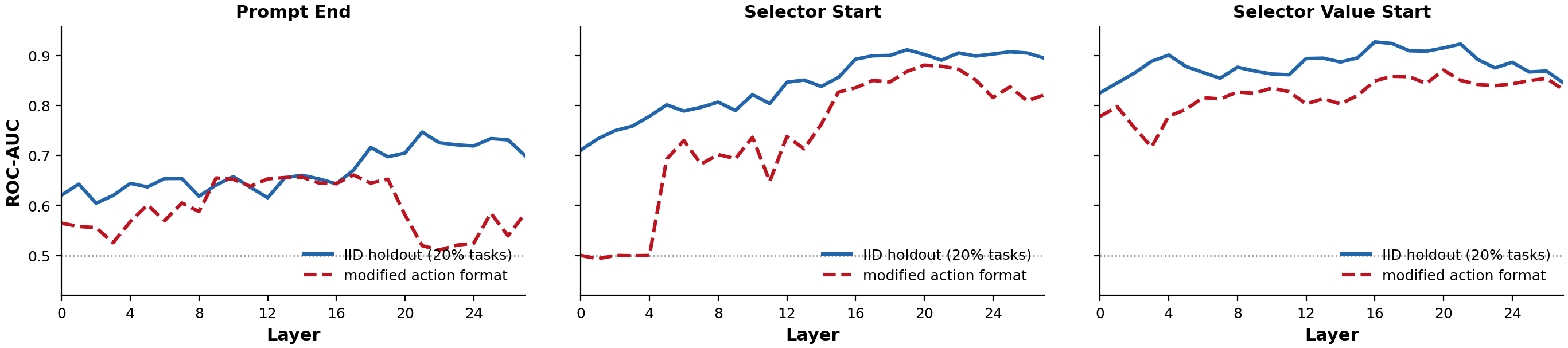
Using the probe weights as a steering vector, we can reduce hallucinations by as much as 85% at selector_start L17, while shifting only 7% of valid cases to hallucinations. This confirms a causal role for the probed direction. However, when the action list format is changed from JSON to numbered markdown — with no change to the underlying task — probe performance degrades substantially and steering effectiveness drops significantly.
Observation 6 Distributional Mismatch of SAEs: Pretrained SAEs Do Not Yield Clearly Interpretable Features
We apply a pretrained BatchTopK SAE (dictionary size 131,072, sparsity k=64) for Qwen2.5-7B-Instruct to residual stream representations at layer 27 — the layer with the highest causal recovery from activation patching. For each trial, we pass the residual stream through the SAE, take the maximum activation per feature across token positions, and average within each class. We then identify which tokens each feature most promotes via its dot product with the unembedding matrix.
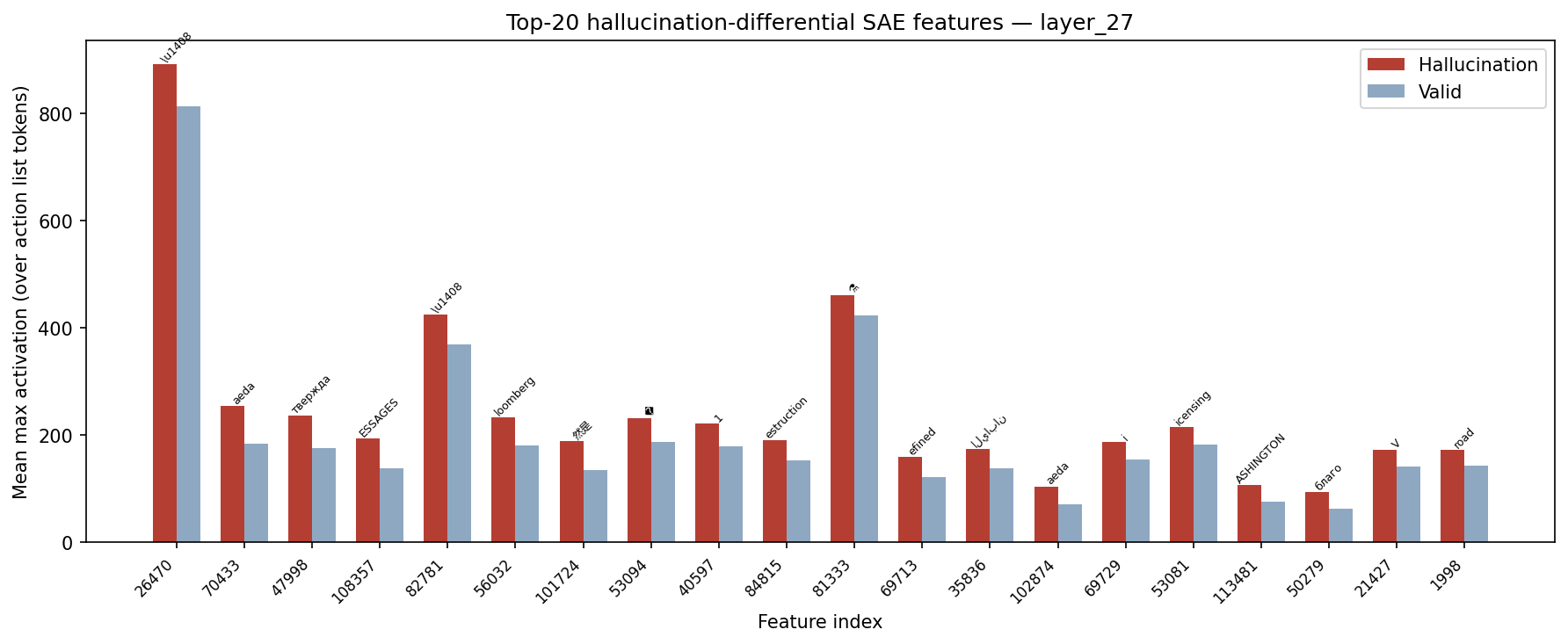
The top features differentiating hallucinated from valid cases do not correspond to anything interpretable about web navigation, action selection, or strategy commitment. This is consistent with the distributional mismatch challenge: SAEs trained on static text corpora learn features reflecting what is statistically prevalent in text. Concepts relevant to agentic behavior — goal tracking, tool selection, commitment to multi-step strategies — arise from environment interaction and are largely absent from static text corpora, and may therefore not be recoverable from a pretrained SAE.
Further Discussion
The paper includes detailed discussions of how these challenges generalize to other agent types (embodied, tool-calling, code generation) and addresses common alternative views on whether MI is necessary for agents.
How These Challenges Generalize Beyond Web Agents
Although the results of our case study are specific to web navigation, the same MI challenges arise across agent settings. In embodied settings, agents struggle with path and motion planning even in simple environments, and their decisions can be driven by unreliable representations that produce plausible but environmentally ungrounded reasoning chains, leading to degenerative cycles in which an agent commits to an action sequence that violates environmental preconditions and corrupts subsequent belief states. In tool calling agents, hallucinations arise not from generation errors but from incorrect tool selection strategies that later steps cannot recover from. In code generation agents, failures are distinguished not by individual generation errors but by early diagnostic mistakes that propagate into repair strategies. Across all three settings, the causal origin of failure can be distributed across the trajectory, the environment state changes at every timestep, and failure is jointly determined by model computation and external dynamics, which are the same difficulties our case study identifies.
Alternative Views
Causal MI tools applied more carefully will scale to agents. One might argue that with more careful experimental design, existing MI tools can be extended to cover agent settings. We do not dispute that they can yield partial insights: our own case study shows that activation patching can identify the action list as a causal contributor, and probing can confirm that a hallucination-predictive direction exists before generation begins. But partial insights of this kind fall short of full actionable explanations. When causal load is distributed across many components, single-component attribution can quickly become intractable and standard counterfactual methods can fail as the number of variables increases. These are fundamental challenges of realistic dynamic settings that full causal tools and methods are not able to handle (yet).
We do not need MI for agents; behavioral evaluation is sufficient. Another objection is that behavioral evaluation is sufficient for improving agent reliability without opening the model. We agree that behavioral interpretability is necessary; however, it cannot tell us why agents fail at the level of internal computation, only that and when they do. A failure mode that occurs rarely may not be reliably caught during evaluation, but this does not mean it should be tolerated, given the stakes of real-world agent deployment. Combining MI with behavioral evaluation can help close this gap: if we can identify the mechanisms a model uses to commit to plans, we can monitor those components to predict and prevent failures before they manifest in behavior.
Data-curated training and alignment techniques are sufficient to fix agent failures. Some might argue that agent failures are best addressed through data-curated training rather than interpretability. Improved training will reduce such failures, but it is insufficient on its own: training-based fixes consist of observing failures without understanding the mechanisms that produced them. Training can therefore corrupt internal representations in ways behavioral evaluation may not detect and MI can help untangle. Furthermore, MI can also be useful for designing more targeted training approaches that intervene precisely on the components responsible for the behavior, yielding more efficient training and representations that remain disentangled from unrelated behaviors.
A Roadmap for MI for LLM Agents
Our case study identifies concrete challenges that future work needs to address. We outline five research directions.
MI benchmarks for agentic applications
No MI benchmarks exist for agent settings. A benchmark for agentic MI must specify not just a task and model but an environment, a trajectory distribution, and ground truth for both trajectory-level failures and what triggered them. It must define what a correct mechanistic explanation looks like and provide evaluation criteria for faithfulness, completeness, and actionability.
Move beyond single-component causal attribution
When computation is distributed across many components and timesteps, single-component attribution methods become insufficient. MI for agents likely needs to combine correlational approaches to surface candidate components with targeted causal verification, rather than relying solely on activation patching over a single forward pass.
Construct counterfactuals in stateful environments
Clean interpretable counterfactuals are rarely possible in realistic agentic settings: valid and hallucinated actions can come from entirely different pages, tasks, and histories. New methods are needed for constructing or approximating counterfactuals in dynamic environments where state spaces are open-ended and trajectories are highly variable.
Feature discovery for agentic distributions
Agentic settings introduce conceptual primitives — goal tracking, commitments to multi-step strategies, representations of environment dynamics — with no natural analog in existing feature ontologies. Progress requires training SAEs on agentic data, developing approaches that can recover richer geometric structure, and building agentic feature ontologies organized around agent components.
Monitoring model beliefs across timesteps
Even when a failure is clearly observable at the output, it is not straightforward to determine when the model committed to the wrong strategy or how its internal representations evolved to that point. Methods are needed that can track the emergence of a plan across both layers and timesteps, and identify when the model transitions from open exploration to a fixed commitment.
Conclusion
Our case study of web element hallucination illustrates a broader challenge: standard MI tools — activation patching, linear probes, SAEs, targeted interventions — each yield partial insights into this failure mode, but none yield a complete mechanistic explanation of why the model commits to a hallucinated strategy. The best intervention we found fixes only 8.9% of hallucinated cases despite extensive search over component combinations. We believe this reflects structural challenges of agentic settings that are not specific to this failure mode or model, and that addressing them requires new methods that treat agent planning as an object of mechanistic study.